The Setup
I bought a used Intel NUC, loaded it with 64 GB of RAM, and told myself the standard story: cloud APIs are expensive, my hardware is paid for, the math has to be on my side.
A few weeks in, I sat down to actually measure it.
The math is not on my side. The math is openly hostile to my side. And the most interesting thing I learned isn't that local is slow — it's that "free" turned out to be a much more expensive word than I had given it credit for.
The Benchmark
Three classes of inference. Same three prompts. Same methodology. Five runs per cell, median wall-clock.
- Local — qwen2.5:7b, qwen2.5:14b, llama3.1:8b on Polaris (12-core CPU, 64 GB RAM, no GPU). Q4 quantized, served by Ollama.
- Paid cloud — DeepSeek V4 Flash and V4 Pro.
- Free cloud —
nvidia/nemotron-3-super-120b-a12bvia Nvidia's free-tier API. 120B parameter reasoning model. No credit card.
Three prompt sizes: a ~50-token chat question, a ~400-token code review, and a ~1500-token agent-style prompt with full tool definitions.
| Backend | Model | Prompt | Wall (s) | Output tok | Tok/s |
|---|---|---|---|---|---|
| Local | qwen2.5:7b | short | 23 | 177 | 7 |
| Local | qwen2.5:7b | medium | 148 | 1,039 | 7 |
| Local | qwen2.5:7b | long | 123 | 818 | 6 |
| Local | qwen2.5:14b | long | 214 | 727 | 3 |
| Local | llama3.1:8b | long | 100 | 608 | 6 |
| Paid | deepseek-v4-flash | short | 10 | 618 | 60 |
| Paid | deepseek-v4-flash | long | 34 | 2,243 | 64 |
| Paid | deepseek-v4-pro | medium | 113 | 3,624 | 32 |
| Free | nemotron-3-super | short | 10 | 338 | 35 |
| Free | nemotron-3-super | long | 120 | 3,755 | 21 |
The Long-Prompt Row
Read the long-prompt rows together. That's the row that matches what an agent framework actually sends — system prompt, tool definitions, conversation history, all bundled into one request.
- DeepSeek V4 Flash, paid: 34 seconds.
- Nvidia Nemotron, free: 120 seconds.
- qwen2.5:7b, local: 123 seconds.
The free cloud option and the local option are the same speed. Both are roughly four times slower than the paid one.
Why "Free" Is Slow
Two effects compound, and both are worth naming.
Rate-Limited Shared Infrastructure
Free-tier inference on a frontier-grade model is a marketing funnel, not a charity. The provider serves your request when their paying customers don't need the GPU. Public benchmarks for hosted Nemotron 3 Super clock it at ~178 tok/sec. I'm getting 21. That's the queueing tax — not a bug, the business model.
Reasoning-Model Verbosity
Nemotron 3 Super is a reasoning model. It generates a thinking trace before its answer. For my long prompt, it produced 3,755 output tokens — 67% more than DeepSeek V4 Flash for the same question. Even at the same throughput, more tokens equals more wall-clock.
The reasoning is presumably better. For the kind of question your assistant gets ten times a day — "what's on my calendar," "summarize this email" — you don't need reasoning. You need the answer.
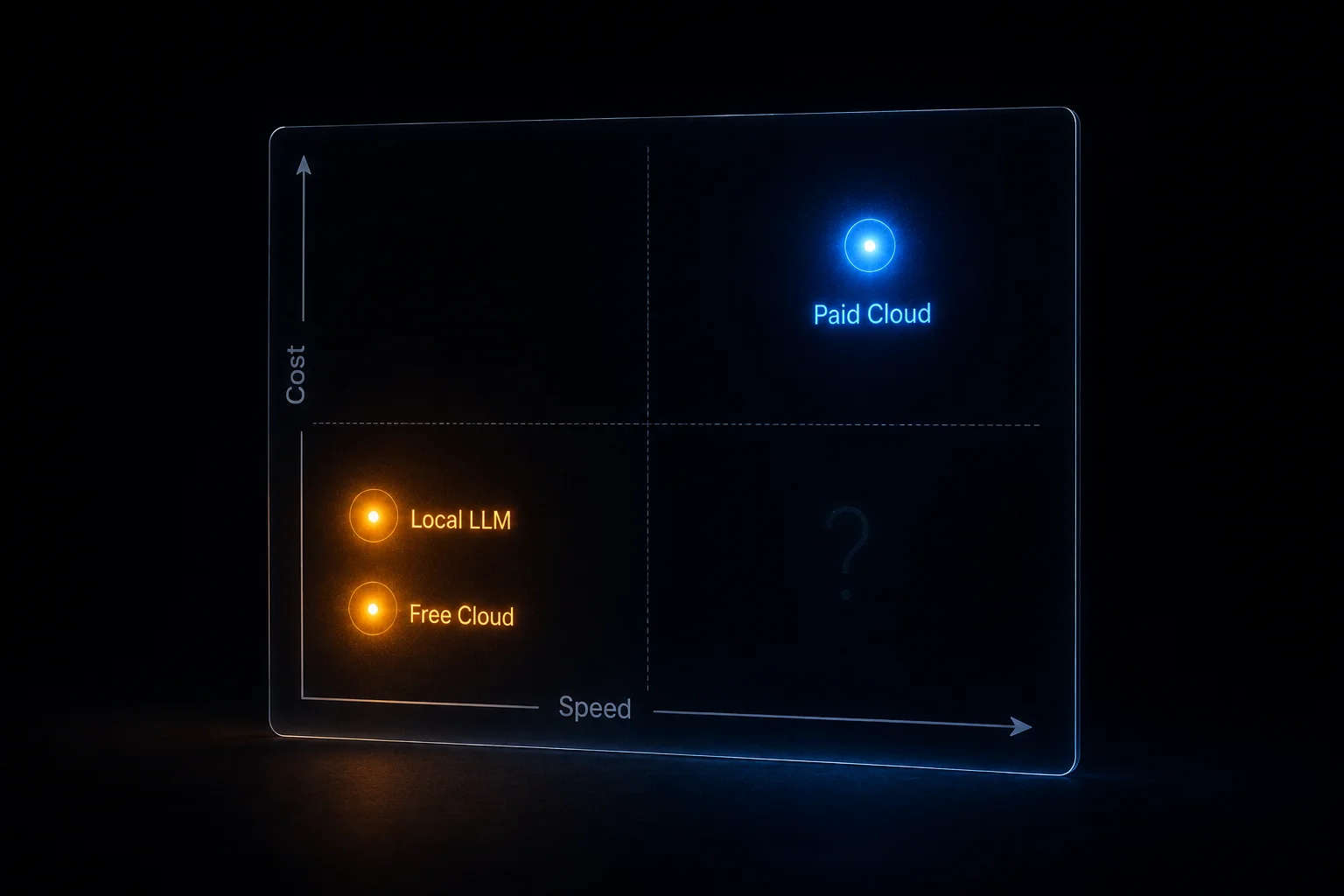
The Empty Quadrant
Plot the available options on speed × cost and a pattern shows up.
The fast-and-free quadrant is empty. Not "underexplored," not "emerging" — empty.
Inference at frontier-model speed costs real money in GPUs and electricity. Someone is always paying for those tokens. If it isn't you, it's the provider — and they will throttle you to recoup the cost in time, ads, or eventual conversion to paid. The throttling is the point.
So the actual choice is not local-vs-cloud or free-vs-paid. The actual choice is which dimension you spend on: dollars, latency, or hardware. Pick one. There is no fourth option.
What This Means for Personal Use
For a personal assistant doing 50–100 messages a day, the math is cleaner than I expected.
- Paid cloud at DeepSeek V4 Flash prices works out to a few dollars a year. Latency feels like chat.
- Free cloud is genuinely free in dollars but the latency makes it unusable for ambient assistant work. A two-minute weather query is not a weather query — it's a phone tree.
- Local on CPU is free in dollars too, with the same latency penalty. The advantage local does have is privacy and offline — different reasons to run local, and they shouldn't be conflated with cost.
The cheapest viable option turned out to be the paid one. That's not the sentence I expected to write.
What Local LLMs Are Actually For
The takeaway isn't "don't run local models." The takeaway is that most people, including me, are running them for the wrong reason.
What Polaris is good at, that I underrated:
- Embeddings —
nomic-embed-textruns at functionally infinite speed for personal volumes - Batch async work — overnight summarisation, classification, periodic re-indexing
- Privacy-required workloads — journaling, financial parsing, anything you'd never send to an API
- Offline — when the network is bad, local still works
What it's bad at, that I overrated:
- Interactive chat — the latency floor is too high
- Tool-heavy agent workloads — long system prompts kill CPU prompt processing
- Reasoning at scale — bigger local models scale negatively in tokens-per-second per parameter
The hardware isn't wasted. I just bought it for the job it's worst at.
The Reframe
If I could send this post back to myself two months ago, the line that would have saved me the most time isn't about cost. It's this:
Fast inference is the artifact of someone, somewhere, paying for a GPU to be on. Whether that's you (hardware), them (API), or "later" (free tier with throttle) — the GPU has to be there and it has to be running. There is no model where the GPU is paid for and the throughput is yours and the price is zero. Pick two.
I picked hardware, then complained about latency. The market answer was already there: pay for inference. Don't host it. A few dollars a year gets you what no NUC and no free tier can match.
The economics were never against local LLMs. They were against using local LLMs for the things cloud LLMs are obviously better at.
Up Next
Polaris stays on. The role has shifted: embeddings, batch work, privacy-required tasks, fallback when the network is down. The interactive assistant gets routed to DeepSeek V4 Flash by default, with reasoning escalation for the rare question that warrants it.
The post I won't write is "I tore down Polaris." The post I'll probably write next is "What I built once I stopped trying to make it the brain."
If you're standing where I was — about to buy hardware to run local LLMs for a personal assistant — let me save you the experiment. Buy the NUC if you want to learn Linux, host services, do batch work, or experiment with the parts of LLMs that aren't interactive chat. If you want a chat assistant, just use the API.
The math is openly on your side.